
ACL2022共收录4篇词义消歧论文,3篇来自一个意大利科研团队
作者 | Antonio
编辑 | 陈彩娴
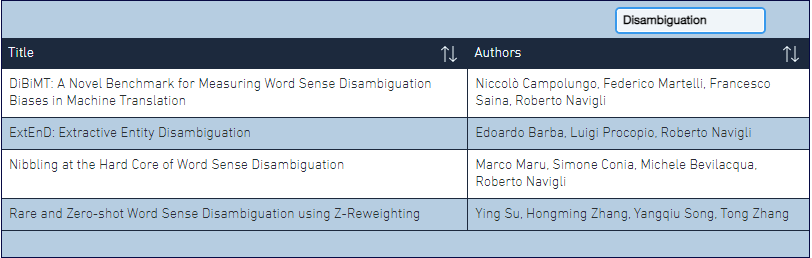
ACL 2022已经于近期正式在官网上刊登了录取的文章,其中涉及到词义消歧(Word Sense Disambiguation, WSD)的文章共有4篇,参考下图的查询。
WSD是指识别出有多个义项的目标词汇在上下文中的含义,是NLP中一个重要并且具有NP-hard复杂度的任务,不仅可以帮助机器更好地识别词汇语义,还对机器翻译、文本理解等下游任务起到辅助作用。
本文简要整理并介绍其中已经公布了论文全文的前三篇,值得注意的是,这三篇都出自同一个课题组,即来自意大利罗马一大的Sapienza NLP,导师为Roberto Navigli。
打开凤凰新闻,查看更多高清图片(ACL 22上关于WSD的论文)
1
WSD真的超过了人类性能了吗?

论文题目:Nibbling at the Hard Core ofWord Sense Disambiguation
本文是一篇评测以往的WSD方法的分析型论文,并根据对于当前方法的不足,提出了更加富有挑战性的数据集和评测指标。具体而言:
1、文章从定性和定量两个方面,仔细分析了7个当前最SOTA的模型都会存在的一些错误和偏差。这些模型都是经典模型,并且在当时达到过最佳性能。它们分别是基于判别式的ARES,BEM,ESCHER(当前SOTA),EWISER, GlossBERT;基于生成式的Generationary;和无监督训练的SyntagRank模型。值得注意的是,这7个模型中有5个模型是属于Roberto课题组。
考虑到理想的模型应该表现得和人类类似的假设,现有模型在WSD上犯得很多错误是低级和违背常识的。例如下面的例子:
ESCHER是当前SOTA模型,在上述对于母语者看来wind一定不会是空气的含义,但模型却判断错误。
从定量的角度,文章重点分析了WSD中非常常见的不平衡问题——最频繁释义偏差(MFS)和训练数据偏差,即测试集中存在训练集中从未见过的释义。这两个问题都由知识不确定性(epistemic uncertainty)导致的。从定性角度,文章则分析了标注者偏差,这属于固有的随机不确定性(aleatoric uncertainty),一个语言学专家标注了测试集出现的6类偏差,并做了详细分析。
2、出于上述偏差的分析,文章也提出了一系列更硬核的评测测试集合,即42D,42个语言domain,并且对于那些不常出现的释义目标也做了很好的评估。
同时研究者们提出了修正了原有的micro-averaged的F1得分,而变成了macro-average的F1得分。
最后,文章收集了在上述模型中都难以分对的那些实例,命名为“hardEN”。换句话说这个所有的模型对于这个测试集的F1得分都为0。这样对于之后模型评估设计了一个很难的试金石。
2
用来衡量机器翻译中的WSD的测试基准
论文题目:DIBIMT: A Novel Benchmark for Measuring Word Sense Disambiguation Biases in Machine Translation
一词多义现象在机器翻译中显得尤为突出,这也是机器翻译中常常出现的偏差的原因。文章研究了机器翻译中的多义性偏差现象,并且提出了一个全新的测试基准,包含针对多种语言的测试集以及评价指标。具体来看,文章的贡献有:
1、文章针对英语作为源语言,五种语言(中文、德文、意大利语、俄罗斯语和西班牙语)作为目标语言,标注了常见的WSD中出现的带有歧义词的正负样例,如下图展示了一个样例,显示了英文中shot在不同语言中的正误翻译:
文章详细描述了句子的收集过程,包括语言库选择、句子清洗和过滤、数据集标注等。下图展示了数据集的标注统计量:
其中数据集主要收集了名词和动词。之后由于数据集是从BabelNet中收集的,文中则定义了好的和坏的释义集,并且统计了多大比例的释义被标注者添加(OG);多大比例被移除(RG)和两句例句使用同一释义的比例(SL),统计量如下:
2、除了准确率,文章定义了四种全新的评价指标,用来衡量频率和词义的关系,它们分别是:Sense Frequency Index Influence (SFII),Sense Polysemy Degree Importance (SPDI),Most and More Frequent Senses相关的两个MFS和MFS+。
3、文章比较了5类SOTA的机器翻译系统,包含两类商业系统:DeepL Translator,Google Translator和三类非商业模型,包含:OPUS,MBart50和M2M100。它们在五类语言上的分类结果参考下图:
从准确率上可以看出,DeepL的性能要显著得比其它方法更好。
在细粒度分析歧义的新指标上,也有类似的趋势:
之后,文章还探讨了很多有意思的语言学分析,比如,是否动词要比名词更难翻译?编码器是否真的可以去歧义等等?有兴趣的读者可以找来文章细细阅读。
代码和评测平台之后会放出:https://nlp.uniroma1.it/dibimt
3
实体去歧义任务的新定义
论文标题:ExtEnD: Extractive Entity Disambiguation
文章对WSD内的一个更加细粒度的实体去歧义的任务进行了新的方式去定义,即把它当作一个文本抽取的任务,并且采用两个Transformer模型架构实现(命名为EXTEND)。EXTEND在6个评价数据库中有4个在F1 score上都达到了SOTA水平。
实体是指关系网络中的节点,相比WSD中更加宽泛的词汇,实体名词往往更具有实际意义,并且更有多义性的可能性,下面展示了一个例子,选出Metropolis可能指的是哪个场景下的。
具体而言,如下图,EXTEND架构首先将输入的上下文和所有的候选项拼接在一起,模型的输出则是目标选项的起始和终止的单词索引。其中,提取特征的部分是Longformer,之后的head采用简单的FC输出每一个词汇可能成为起始和终止的概率。
事实上,将WSD定义为这种文本提取的方式在之前的方法ESC和ESCHER中被两次用到(都是同一位作者),其中的ESCHER方法是当前WSD的SOTA方法,这启发我们这种截取式方式的有效性。
以下是模型在6个数据集上的表现,它在其中的4个上面达到了最优的水平。
4
关于课题组
如前述所示,这三项工作都是由Roberto Navigli领导的课题组完成的。在WSD领域内,该课题组就承包了大半工作,包含模型的提出、新任务的定义、数据集语料库的建设、富有启发的分析等等。而Roberto本人也一直专注于这一领域,其博士毕业论文就是关于WSD的;而实验室成员的很多研究方向也都几乎包含这个领域,这是从不同的角度去挖掘,例如多语等。
这种几十年如一日的专注确实很令人敬佩,这可能也是课题组不断可以产出高质量的WSD文章的重要原因。实验室主页就有详细的文章介绍,对这一领域感兴趣的同学一定要随时关注。
相关文章
SQL Error: select id,classid,MATCH(title) AGAINST('ACL2022 25184253 42533428 4 38102042 20425069 50694791 47913871' IN BOOLEAN MODE) as jhc from ***_enewssearchall where (id<>361884) and MATCH(title) AGAINST('ACL2022 25184253 42533428 4 38102042 20425069 50694791 47913871' IN BOOLEAN MODE) order by jhc desc,infotime desc limit 0, 6相关推荐
Warning: Invalid argument supplied for foreach() in /www/wwwroot/guniangcha.com/e/class/userfun.php on line 15